
About My Profession
Mailing System
Background
A couple of years into my employment at Computer Graphics they would secure a couple of bank clients that would change the business from primarily mail processing to data processing prep for mailing programs. For several years they were simply doing the printing. These were what we called form fill jobs. The background letter text was printed on one of our printers (each one had the same print chain) and that was taken to an offset printer where the computer forms were printed. We would then take those forms again through one of our printers and supply the variable information: Name, Address, City State Zip, and the honorific greeting (e.g., Mr. Sample A. Sample). As part of this process we did an upper/lower case conversion on the names and addresses and added punctuation.
A Golden Opportunity
We finally got the chance to do the upfront data processing (data scrub, address standardization, NCOA, and mail population selection). But it was a job like no other they'd encountered in their careers. These bank clients didn't have firm specs. In fact, my boss, Ron, called the specs the "Official List of Clues." I was trained as a systems analyst in college and the proper (and only) way to do a system is to get all of the specifications upfront and only when these are finalized does the computer programming start. But the problem was these bank clients had only had a general idea of what they needed and we had to figure it out in an interactive process. This meant starting the job and then making adjustments according to what the data dictated. I was brought into a job for Wells Fargo that was already 2 weeks in and starting with an input population of over 2 million records it had gone through 20 steps which had wittled it down to around 450,000. They were looking for at least 600,000 and they wanted to know where all the deleted records went with the idea that some of those records would be undeleted.

The flowchart of the Wells Fargo process.
It took the better part of a day, but I got the figures they were looking for and I really impressed them. We were then able to find some 150,000 additional records so they'd have the 600,000 they were looking for. I knew there had to be a better way.
Another Bank - A New Process
They secured another bank (First Interstate) and they assigned it to me. The process Ron had used for Wells Fargo made perfect sense if the job specifications were set in stone. Each step if records were unwanted they were purged from the input universe so there would be fewer records to process going forward. But I knew there was a simple solution: don't purge any records! Instead, the records would be tagged. I created an edit field in the file that was 16 characters long and was binary. With each character (i.e., byte) composed of 8 bits, that meant I had 16 X 8 (128) possible edits. And if I ever needed more (which didn't happen), I could easily make the field longer.
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
Edits 001 - 008 009 - 016 ...
At the beginning of the process this edit field was completely zeroed out so all binary zeroes. In IBM assembler an XC (Exclusive OR) instruction of the field against itself: XC EDITFLD,EDITFLD. Then there was a 3 character final edit code field. A single edit bit position was firmly named (001-128), but it's edit assignment was not. And at the time any bit was set did not necessarily mean this would be a fatal edit. That could change at any point during the process. And for what we called the "waterfall" report (the suppressions in order of their hierarchy), we'd set that hierarchy. A record could have multiple bits set that were fatal edits, but only one of them would appear on the report. To establish the definitions, hierarchy, and fatality, we had a simple table. I used a card header deck (virtual, of course) as it was convenient and could be easily included in any program deck. The first position was actually a carriage control character as it was designed to be printed out to be shared with the client. At program execution, the deck was read in and put into a table.
1
0 JOB: J-00000 JOB SUPPRESSION CODES XX/XX/XX
- 001 A DUPLICATE HOUSEHOLD RECORDS WITH THE SAME SURNAME
0 002* DUPLICATE ADDRESS
0 006 B CLOSED FILE DUPLICATION
0 007 B MASTER FILE DUPLICATION
0 008 B COMPLAINT FILE DUPLICATION
0 009 B DECLINE FILE DUPLICATION
0 004 C COLLECTION / NO-PANDER DUPLICATION
0 005 C SURNAMES WITH TOO FEW CHARACTERS AND NO VOWELS (3 IS DEFAULT)
0 018 C SURNAMES WITH OVER X CHARACTERS (18 IS THE DEFAULT)
0 013 C UNABLE TO NAME STANDARDIZE
0 014 C P. O. BOXES
0 019 C INVALID ZIP CODE (TRAILING 00 OR NON-NUMERIC)
0 021 C ZIP CODE NOT ON POSTAL ZIP MASTER
The fields:
1-2 Ignored
3-5 Edit Code. 001-nnn Defines the edit bit position.
6-6 * or blank. If blank, the edit is fatal. If an *, it is not.
7-7 Edit class (A-Z) Used to group edits for reporting purposes
8-8 Unused
9-71 Edit description
The whole idea here is that while processing is ongoing we set edits without regard to their hierarchy or whether they will actually be a fatal edit. These can change as the job proceeds. We also set edits without regard to any previous edit so they're completely independent. So if the output is not as expected (or needed) we could easily do "what if" scenarios.
Processing on Disk - Update in Place
This system was implemented for magnetic tape, first with 9-track tapes and later with the much more reliable cartridge tapes. Disk would have been definitely preferred, but tape was necessary because the number of input records regularly exceeded 10 million. However, from day one I dreamed that one day I would have enough disk storage so I'd essentially have all the gross input records in one physical file. I would then do the process in what is called an "update in place." Physically, you read the record, process it, and write it back onto the disk in that same position.
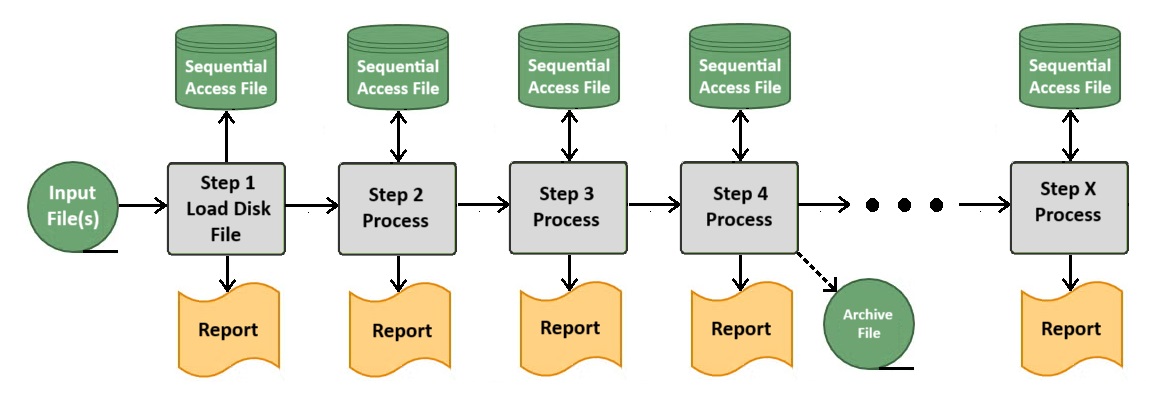
Of course, this technique was not without risk. It was relatively easy to accidently overwrite the data. So every 3rd or 4th step the disk file was offloaded onto tape for temporary archiving. But the standard update program shell had other built in safeguards. Key sections of the input record (parts that are never updated during the process) are saved and before the record is written these areas are checked to be sure they are unchanged. If they are, the job is immediately cancelled. I should mention this offered the chance to speed up the process by doing some overlap. In typical tape sequential processing, you couldn't start the the next step until the previous one completed. But in this disk process you could do exactly that. This was also not without an important risk. The step executing behind better not catch up to the one ahead! So where were we in the process? We would display checkpoints on the operator console, generally when a million records were processed.
After I left Computer Graphics I would learn that the update in place methodology was abandoned because of the fear of accidently destroying the database. So they did strictly tape processing.